
GitHub strange
Earlier this year, I was paired up with my colleagues Chris, Tom, Madan and intern Danielle Gonzalez (from Rochester) for the annual Microsoft Hackathon. The goal was to examine and extract meaningful data from GHTorrent, a colossal data set that contains an exhaustive log of all GitHub events, for all repositories.
Nothing went quite as planned, and we (of course) hit more issues than we anticipated, but in the short span of a couple days we still managed to make some interesting discoveries. In particular, we found some really weird GitHub repositories that to this day raise more questions than answers… Here’s (finally) a writeup!
A monstrous dataset
The dataset was colossal: even on a fine, 20MB/s network connection, merely downloading 100GB of data still takes about two hours… and that’s just for a month’s worth of data. So, there went the first few hours of the hackathon.
The next issue was simply that my machine, even with 1TB of disk, just didn’t have enough space to load the downloaded SQL dump into a local MySQL database; even if I had had the space, according to our extrapolations, this would’ve taken several days. So, we had to come up with a plan B.
A quick language shootout ensued, where we each wrote a quick-and-dirty script that would parse a couple of the SQL dumped tables (in CSV format) and try to compute some basic queries by hand. Perl, Unix shell (grep & co), and OCaml were all attempted. We found that using the excellent CSV package for OCaml gave the fastest results (much more so than a hand-writter lexer); they even had the exact option we needed to parse the specific escaping format used by SQL dumps.
The strange world of GitHub repositories
We then attempted to answer a very simple question in our remaining time: which repositories have the most commits? (Over the course of that month.)
It turns out that because we were aggregating and folding over the entire event stream of GitHub, instead of counting the number of commits currently in the tree, we appear to have counted the number of commits pushed to a given repository over the chosen time period. The results were not what we expected, and uncovered some repositories that are not what you can read about, e.g. on this Quora question.
First place: tmp_clock_repo
We initially suspected an error in our script: the first repository on our list
was https://github.com/efarbereger/tmp_clock_repo, with over 13 million
commits. We immediately went to the project page, only to find a nondescript
repository, with no files in it, only 1470 commits, the latest of which was
several days ago. Only after we navigated back up to the
author’s page did everything suddenly became
clear. Eric Farber-Eger, an unsung hero of version control, has a cron job that
every five minutes pushes an entire new history to his repo, crafted so that the
GitHub heat map of his contributions forms a digital LCD clock. And, 31 * 24 *
( 60 / 5 ) * 1470 is about 13 million, so this checks out.
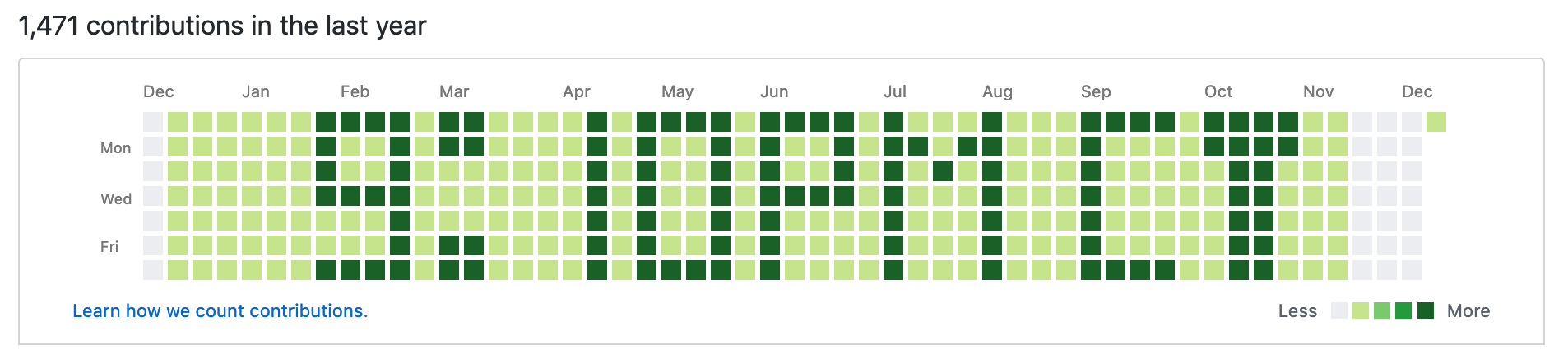
A quick aside: Git allows one to entirely rewrite the history by force-pushing,
and commit metadata is only indicative; in particular, the date of a given
commit can be chosen arbitrarly, either by using a Git library directly (e.g.
libgit2) or via the --date option of the command-line frontend. Thus, the
heatmap can be used as a virtual LCD display where each pixel is addressable by
writing to the (fresh) history commits for that given time period.
I don’t know who Eric is; a Google search doesn’t seem to yield many results; but he has my eternal admiration.
For interested readers, there seems to be an entire set of libraries dedicated to the very task of pushing pixel art on GitHub heatmaps. Some people’s creativity is just astonishing.
Second place: historyclockimage
In second place was a now-defunct project called historyclockimage, at nearly
5 million commits pushed. Quite unsurprisingly, it was under username
efarbereger. My curiosity and admiration for this mystery man only grew
stronger.
Third place: blocklist-ipsets
In third place was https://github.com/firehol/blocklist-ipsets, with 3.5 million commits pushed over time, but only one commit in the history. It turns out that, this is just one instance of people using GitHub as a cloud storage provider, to store a variety of files which, conceivably, can be easily updated by clients via the use of a simple Git pull.
I guess there is something to be said for the simplicity of the Git workflow? Or is it that setting up just storage on the cloud is too much of a setup for trivial use-cases?
Fourth place: heartbeat
In fourth place, with 1.6 million commits, was perhaps the most intringuing
repository: https://github.com/19h/heartbeat. The description reads:
“Emergency signed life insurance files.”. The contents? Three files: a cryptic
README, whose first line is GCM R 20/0c/400 L 20/0c/400 followed by some
base64 data, which once decoded, does not seem to have any structure or
contents. Beyond the README are two files, lkLocation and lkHeartbeat.
I could find very little on this repository, except for a brief Reddit
thread.
What is this mysterious project? Is this a cloud-distributed, modern version of the supposed dead-hand radio UVB-76?
Fifth place: update
In fifth place, with 1.2 million commits:
https://github.com/shenzhouzd/update, which very simply reads: “This
repository has been disabled. Access to this repository has been disabled by
GitHub staff due to excessive use of resources”. What have you done,
shenzhouzd? Why is https://github.com/shenzhouzd/update1 empty?
Special mention: CI logs
Some familiar faces appear further down the line (positions 16 and 52), with CI logs for the impressive infrastructure deployed by our friends at Cambridge Labs.
Very special mention: TV playlists?!!
Further down were a
set
of
repositories all sharing the same characteristics:
a single user, with a single repository of the same name, containing a single
file: lists/plex.txt. The file appears to be a curated playlist of video
channels from across the world; radio stations; and a weird mix of movies hosted
on a public website. Is there some hotel, somewhere, in some part of the world,
where the VOD system pulls its data from GitHub? Who has curated this list and
decided that all the Matrix and Home Alone sequels should be included?
Update: my colleague Tom points out that this seems to be related to http://ccloudtv.org/. I’m unsure why there are many distributed playlists on remote GitHub repositories. Probably for the convenient cloud storage, once again?
Methodology & conclusion
Looking back on the data, this only a very partial view; after all, it’s only over a given month of a given year. It says nothing about the “overall” importance of a given repository; Linux, for instance, is way down.
The goal, however, was not to have super-serious results anyhow, but just to experiment over a short span of time. I’m glad we found oddities and quirky repositories! There are many more mysteries in this list, which I’ve uploaded online. I’d be happy to hear readers’ theories on the mysterious playlists and the life insurance policy.